基础数据操作之二 读取数据源
数据源
对上节的数据还有印象吗?作业有做吗?让我们从上次的数据继续说起。
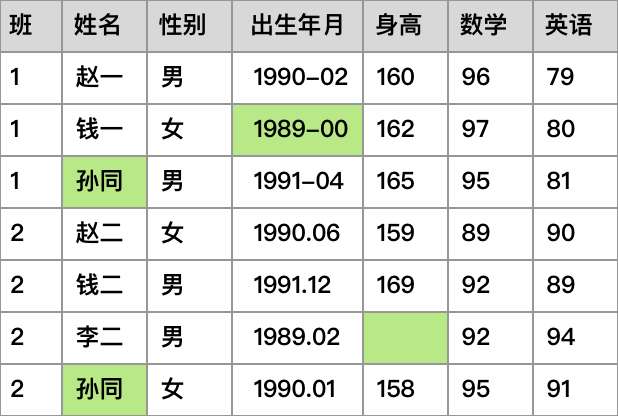
示例数据
真实世界中的数据存在于各种地方,文件中,网页中,数据库中,甚至是剪贴板中。
文件
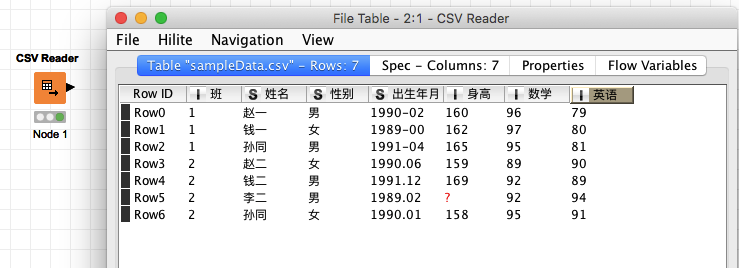
其中,文件分为多种类型,Excel的 XLS 文件,普通的 CSV 文件(逗号分隔文件),JSON文件,HDF5文件等等。以 CSV 文件为例,上面的示例数据可能是这样被记录的:
班,姓名,性别,出生年月,身高,数学,英语
1,赵一,男,1990-02,160,96,79
...
2,李二,男,1989.02,,92,94
...
很简单,就是 约定 了以 "," (英文半角逗号)分隔列中不同的数据,以自然的行来区分数据中不同的行。除了用逗号做为分隔符之外,还可以用其他的标识符,比如分号 ";" ,句号 "。" 或其他什么,只要格式遵从这个列分隔的 约定 就可以。
人们使用 CSV 文件,主要原因就是它其实是一个文本文件(并附加了一些格式进行 约定 ),在所有的平台下都是可以直接打开阅读的。这一点而不像 Excel 的文件格式 xls,数据库等存储数据的方式 -- 需要安装特定的软件,才能查看数据。
对 CSV 文件观察一下,除了之前说的 约定 的分隔符之外,有可能我们拿到的数据有一些 "意外",比如没有表头,即没有 "班,姓名,性别,出生年月,身高,数学,英语" 那一行;或开始时有几行空行;再或者有一些行比其他行短 - 短的主要原因是,那一行后面有一些列没有数据了,就没有写。
哦,对了,在处理中文数据的时候还有可能有关于文件编码的问题绊住我们。
对于这样一个 约定 好了格式,但却仍然有上面所说的"意外"情况的 CSV 文件,在每个分析软件中,都有一些标准的方法去读取。
比如 Python (Pandas库)中就是pandas.read_csv函数, 函数的参数就是上面说的几种情况,外加一些处理"意外"的参数。
在 Excel 中,在导入的时候也是有类似的选项,如下图所示:
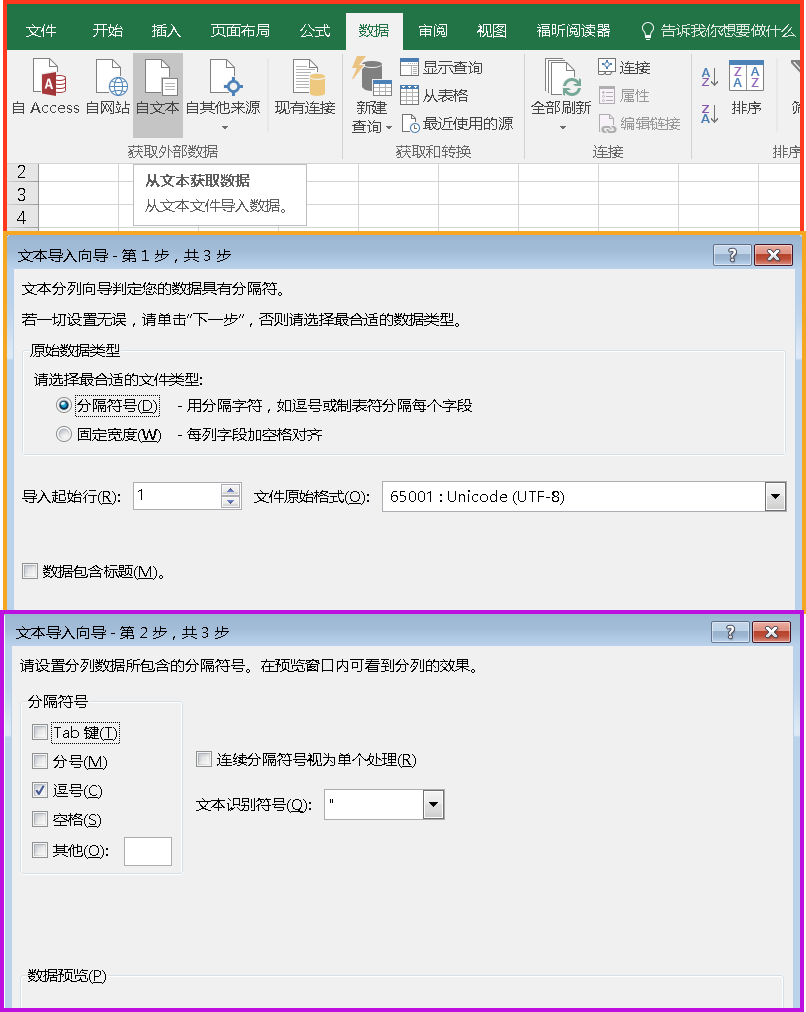
Excel CSV的导入过程
在 R 这门统计语言中,CSV 文件是按照如下方式读取的。即使还不懂这门语言,看着下面语句,也能猜个八九不离十了。
MyData <- read.csv(file="c:/TheDataIWantToReadIn.csv", header=TRUE, sep=",")
KNIME 中,配置下 CSV 节点的参数就可以(KNIME 版本不同时, 下面版本会有所差异),大同小异:
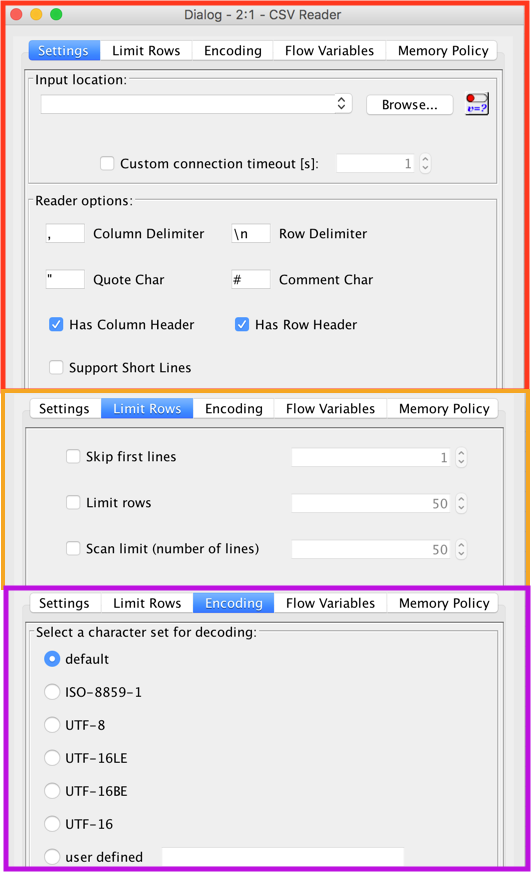
KNIME CSV 节点配置选项
其余的文件类型,以及网页类型(也归类为文件类型),其实只是格式的 约定 差异而已,不再赘言。
数据库
数据库种类繁多,不同的数据库有不同的 约定 连接方式。为简便起见,这里只大概聊两句 KNIME 是怎么连接的。KNIME 底层是由 JAVA 语言写成的,在 JAVA 的世界中,有一个叫做JDBC(Java DataBase Connectivity)的标准,这个标准制定了怎样用 JAVA 去连接数据库,以及怎样在数据库中进行增加,删除,修改,查询(简称为增删改查,CRUD)等一系列操作。各个数据库厂商只需要根据这个标准,制定自己家数据库的相应驱动,就可以在 JAVA 程序中通过 JDBC 接口连接数据库了。下图中的灰色节点,就是各个数据库厂家提供的相应驱动。
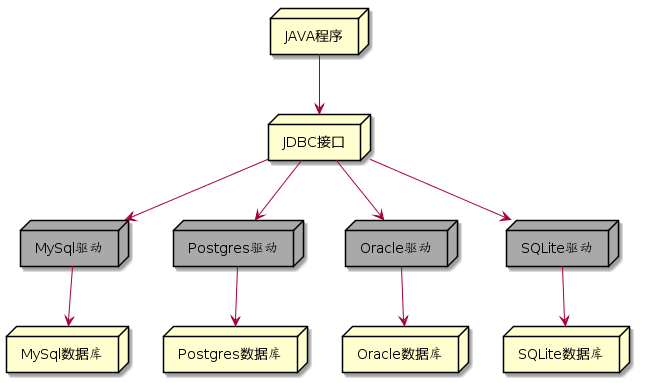
JAVA 程序通过 JDBC 接口连接各种数据库
在 KNIME 中,并不需要做什么特别的操作,就可以连接一些常见的数据库。比如 MySql Connector 就可以直接连接 MySql 数据库(相应的JDBC驱动已经内置),同样,SQLite Connector 就可以直接连接 SQLite 数据库。只有在一些特定的情况下,没有我们要连接的 XXX Connector, 或者想用特定的 JDBC 驱动连接数据库,需要做的就是,把相应的 JDBC 驱动下载下来,然后在 KNIME 中配置一下,最后使用通用的 Database Connector 节点就可以了。具体如何做,请参照 https://www.KNIME.com/database-documentation
本次作业
我们已经准备好了一个工作流, 其中有读取 CSV 数据的节点, 并将整个工作流导出了。
你需要做的就是,把这个工作流想办法导入到你的 KNIME 中,然后试着操作得到下面的结果:
导入 CSV 最终效果图